Ram Cherukuri, MathWorks
18.11.2019, 14:05 Uhr
Deep Learning mit int8-Quantisierung
Ram Cherukuri, Mitarbeiter von MathWorks erklärt in einem Artikel, was int8-Quantisierung ist und warum sie beim Deep Learning mit neuronalen Netzwerken so beliebt ist.
(Quelle: mathworks.com)
Deep-Learning-Einsatz nahezu in Echtzeit ist der Schlüssel zu vielen Anwendungsbereichen. Es reduziert die Kosten für die Kommunikation mit der Cloud in Bezug auf Netzwerkbandbreite, Netzwerklatenz und Stromverbrauch erheblich. Edge-Geräte haben jedoch einen begrenzten Speicher, Rechenressourcen und Strom. Dies bedeutet, dass ein tief lernendes Netzwerk für den Embedded-Einsatz optimiert werden muss.
Die Int8-Quantisierung ist ein beliebter Ansatz für solche Optimierungen nicht nur für maschinelle Lernframeworks wie TensorFlow und PyTorch, sondern auch für Hardware-Toolchains wie NVIDIA TensorRT und Xilinx DNNDK geworden – vor allem, weil int8 8-Bit-Ganzzahlen anstelle von Gleitkommazahlen und Ganzzahlen statt Gleitkomma-Mathematik verwendet, was sowohl den Speicher- als auch den Rechenaufwand reduziert.
Diese Anforderungen können erheblich sein. So benötigt beispielsweise ein relativ einfaches Netzwerk wie AlexNet über 200 MByte, während ein großes Netzwerk wie VGG-16 über 500 MByte benötigt. Netzwerke dieser Größe passen nicht auf Low-Power-Mikrocontroller und kleinere FPGAs.
Der Artikel von Mathworks-Mitarbeiter Ram Cherukuri wirft einen Blick darauf, was es bedeutet, Zahlen mit 8 Bits darzustellen und zeigt, wie durch die int8-Quantisierung, in der Zahlen als Ganzzahlen dargestellt werden, den Gedächtnis- und Bandbreitenverbrauch um 75 Prozent schrumpfen lassen kann.
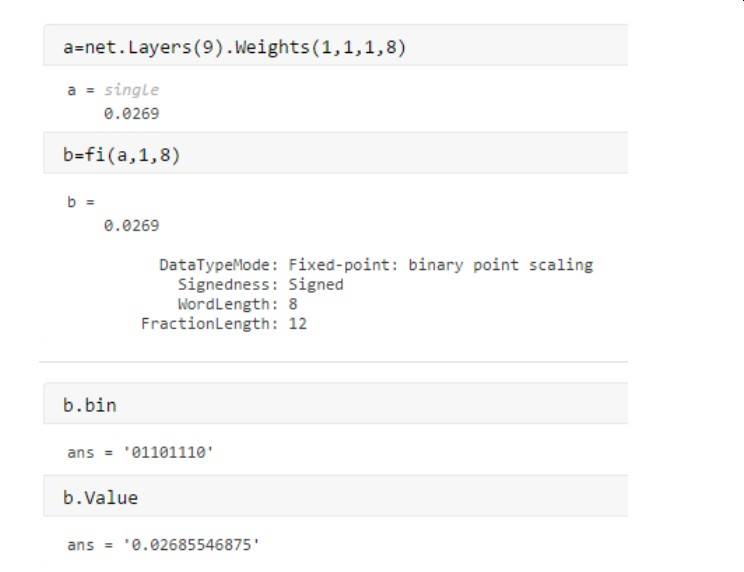
Ein einfaches Beispiel: Der Wert 0,0269 soll als ganze Zahl, erweitert um einen Skalierungsfaktor dargestellt werden. Die Berechnungsformel, um den echten Wert aus dem gespeicherten Integer-Wert wieder zu berechnen lautet:
Echter Wert = gespeicherter Integer-Wert * Skalierungsfaktor Bei der Suche nach dem Skalierungsfaktor hilft die Funktion fi des Programms MATLAB. Es berechnet, dass die man die beste Genauigkeit mit einem Skalierungsfaktor von 2^-12 erhält und das Bitmuster 01101110 gespeichert wird, das die den Integer-Wert 110 darstellt.
Eingesetzt in obige Formel ergibt sich
110 * 2^-12 = 0,02685546875 Das Ergebnis ist nah dran am zu speichernden Wert, aber es bildet ihn nicht exakt ab. Wie man weiter an der Genauigkeit des zu speichernden Wertes arbeiten kann und welche Probleme sich mit dieser Methode ergeben können, ist ebenfalls Thema im englischsprachigen Artikel von Ram Cherukuri, den Sie hier finden.