Graphcore, Aleph Alpha
08.12.2022, 09:40 Uhr
Sparse Modeling: KI-Modell 80 Prozent schlanker
Der europäische KI-Chiphersteller Graphcore und das Heidelberger KI-Unternehmen Aleph Alpha konnten ein KI-Modell mit 13 Milliarden Parametern auf nur noch 2,6 Milliarden Parameter verschlanken und dabei die meisten seiner Fähigkeiten erhalten.
(Quelle: aleph-alpha.com)
Die heute leistungsfähigsten KI-Modelle basieren auf vielen Milliarden von Parametern. Die größten Fortschritte wurden dabei bisher durch Skalierung erreicht. Der Bedarf an benötigter Rechenleistung nimmt allerdings erheblich schneller zu als die Parameteranzahl der KI-Modelle. Dies führt zu immer weiter steigenden Anforderungen was die benötigte Rechenleistung angeht sowie natürlich auch dem damit einhergehenden wachsenden Energieverbrauch der KI-Modelle.
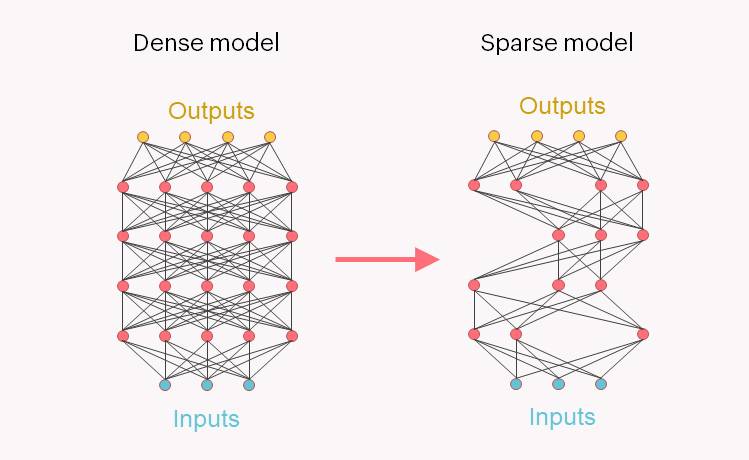
In den bisherigen Dense-Modellen wird ein Großteil der Rechenkapazität für die Durchführung von arithmetischen Operationen an Parametern aufgewandt, die für die behandelte Problemstellung nicht relevant sind, da aussagefähige Parameter in diesen Modellen spärlich verteilt sind ("sparse").
Sparse-Modelle nutzen hingegen neue Verfahren, bei denen – vereinfacht ausgedrückt – die Verarbeitungsleistung auf diejenigen Elemente konzentriert wird, die für die Lösung einer komplexen Aufgabe am wichtigsten sind. Die IPU (Intelligence Processing Unit) des britischen KI-Chipherstellers Graphcore mit ihrem Multiple-Instruction Multiple-Data (MIMD) Design eignet sich hierfür ideal, da sie eine detailliertere Parallelität über mehrere Dimensionen hinweg ermöglicht und Point Sparse Matrix Multiplications unterstützt.
Das Verfahren, durch das circa 80 Prozent des Modellgewichts eliminiert und gleichzeitig die meisten seiner Fähigkeiten erhalten werden konnten, nutzt die von der Graphcore Intelligence Processing Unit (IPU) unterstützten Point Sparse Matrix Multiplications – eine Charakteristik der gezielt für KI-Workloads entwickelten Chiparchitektur.
Die beiden Unternehmen haben auf der Super Computing Conference 2022 (SC22) in Texas eine verschlankte Variante des Conversational Module Lumi von Aleph Alpha vorgestellt. Luminous Base Sparse benötigt nur 20 Prozent der Verarbeitungs-FLOPs und 44 Prozent des Speichers seines Dense-Äquivalents. Von zentraler Bedeutung sei dabei, dass seine 2,6 Milliarden Parameter vollständig auf dem Ultra-High-Speed On-Chip-Memory eines Graphcore IPU-POD16 Classic gehalten werden können, wodurch eine maximale Leistung erzielt werden kann.
Die meisten KI-Anwendungen nutzen momentan Dense Models, bei denen alle Parameter gleichermaßen dargestellt und berechnet werden, unabhängig davon, ob diese zum Modellverhalten beitragen. Dies hat zur Folge, dass wertvolle Verarbeitungszeit und Speicherkapazität für die Speicherung von Parametern und zur Durchführung von Berechnungen mit Parametern verschwendet werden, die keinerlei Auswirkungen haben.
Aleph Alpha und Graphcore ist es gelungen, 80 Prozent des weniger relevanten Modellgewichts zu bereinigen und das Luminous-Modell nur mit den wichtigen Paramentern neu zu trainieren.
Die Anzahl der für Inferenzen erforderlichen FLOPs konnte im Vergleich zum Dense Model auf nur noch 20 Prozent gesenkt werden, während die Speicherbelegung auf 44 Prozent reduziert werden konnte. Dies ist darauf zurückzuführen, dass zusätzliche Kapazität zur Speicherung von Orts- und Wertinformationen für die verbleibenden Non-Zero Parameter benötigt wird. Das Sparse Model, soll außerdem 38 Prozent weniger Energie verbrauchen als das Dense Model.