Chicago Open Rideshare Dataset
02.05.2019, 09:13 Uhr
Massendaten analysieren
Mit Hilfe von Digital Ocean und Postgres analysiert Entwickler Sam Cohen die 17 Millionen Einträge des anonymisierten und öffentlich zugänglichen Chicago Open Rideshare Dataset.
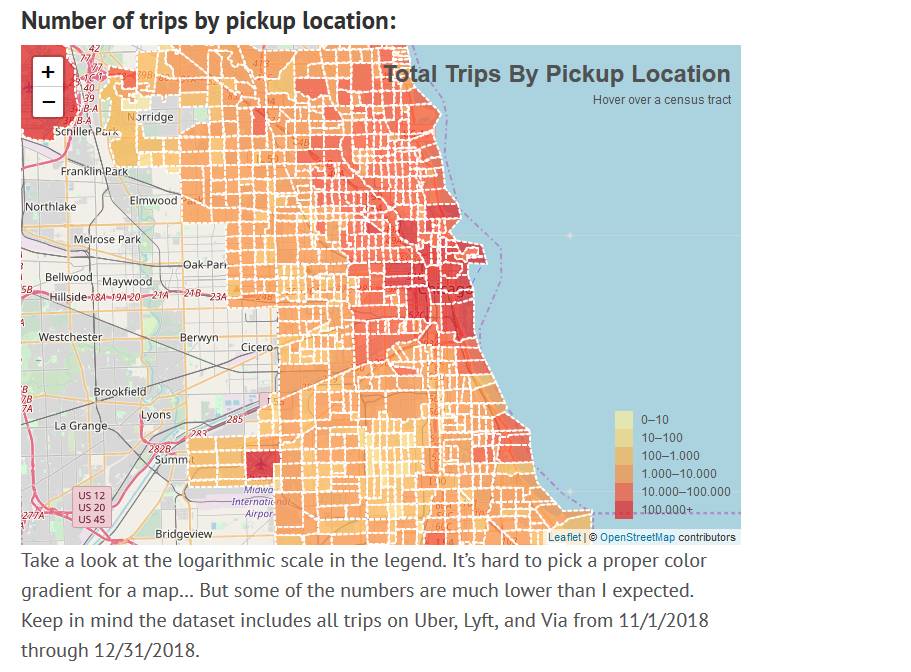
(Quelle: https://samc1213.github.io/2019/04/29/rideshare-dataset-getting-started/)
Das Chicago Open Rideshare Dataset enthält die Daten zu allen Fahrten, die vom 1. November 2018 bis zum 31. Dezember 2018 mit den Diensten Uber, Lyft und Via durchgeführt wurden und entweder in Chicago starteten oder Chicago als Ziel hatten. Es geht dabei um 17 Millionen Datensätze, die anonymisiert wurden und nun öffentlich zugänglich sind. Interessiert an den Möglichkeiten, eine solche Datenmenge zu analysieren hat Entwickler Sam Cohen sich daran gemacht sie zu laden und näher zu untersuchen. Wie er dabei vorgegangen ist, erklärt er in einem Blog Beitrag Schritt für Schritt.
Er nutzt dafür den für kleines Geld nutzbaren Cloudcomputing-Dienst Digital Ocean sowie die Open-Source-Datenbank Postgres. Wie er dabei vorgegangen ist und zu welchen Ergebnissen er gekommen ist, lesen Sie in seinem Blogbeitrag unter https://samc1213.github.io/2019/04/29/rideshare-dataset-getting-started/.
Das Chicago Open Rideshare Dataset wird vierteljährlich erweitert. Inzwischen sind darin die Daten vom 1. November 2018 bis Ende März 2019 enthalten. Mehr Informationen dazu finden Sie hier.